Figure
Weeks of 22nd and 29th
Deadline: August 30th
Once we have all the results, I spent the last week writing the report, while also preparing for my presentation. In terms of the code, I added comments and references, while documenting every changes that I've made in the libraries.
Weeks of 15th and 22nd
Deadline: August 25th
During the first week, I have tried several other ways of preprocessing the Atari images. One of them is to 4 channels instead of one by stacking multiple Atari images in a single input. However, it consumed more memory in the docker container which stops the training midway. For that reason, I decide to stick with the original preprocessing method that is described in the report. I also tried and experiment with other neural networks from other papers, but the experiments showed that the CNN presented in the report has better performance.
Atari Wrapper for a set of Atari environmentsDuring the past workloads, I've wanted the agent to train on multiple Atari environments, instead of a single one. Therefore, I created a wrapper that lets the agent to switch different Atari games throughout the training process.
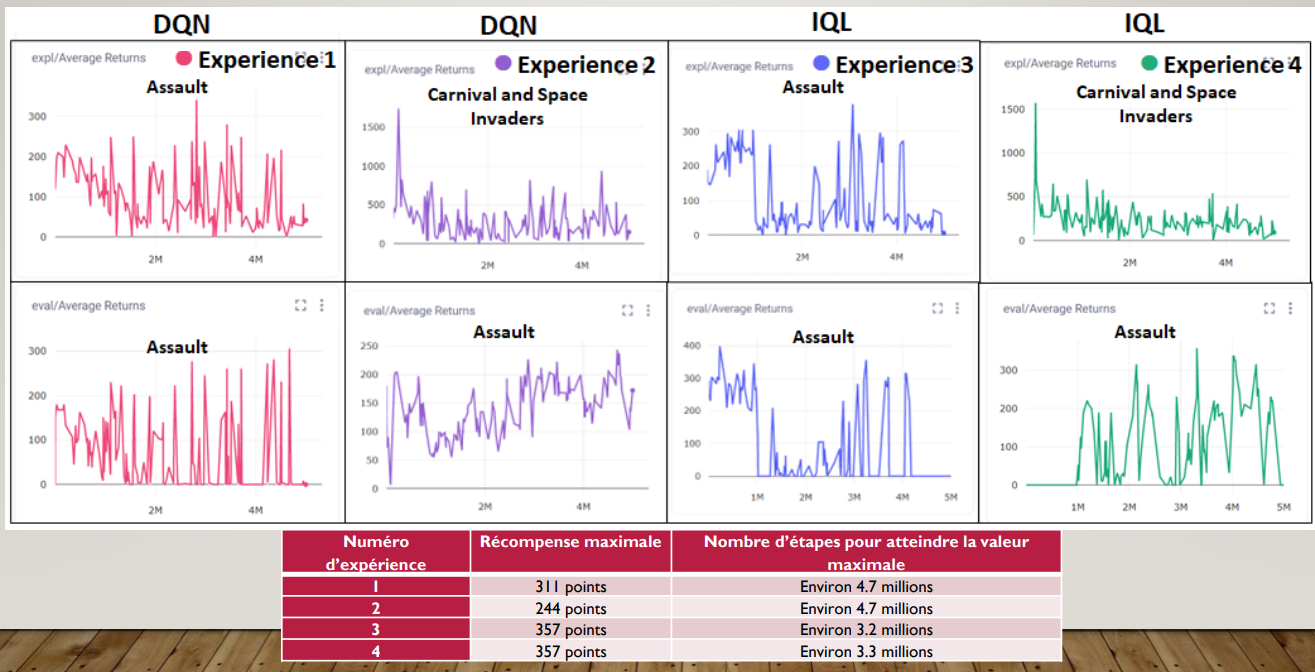
Read paper about Offline RL with IQLIn terms of using Zero-Shot Meta Learning, I decided to implement the algorithm IQL. Then, we compared the agent who trained in DQN algorithm and see if the proposed method lets the agent to generalize for similar tasks. Here are the graphs that I've got from the different experiments. In terms of discussion of these graphs, consult Discussion and Results in the report. Note that instead of using Space Invaders as our Atari game for the test environment, we switched it to Assault due to implementation issues.
Week of August 8th and 15th
Deadline: August 16th
The first solution during the previous workload was to directly run into the docker image in the lab computer. After several attempts, I managed to fully solve the issue. The GPU can recognize the experiment and it has been used for the experiments with ssh mode. The results of this solution are the same as the ones shown in the last figure of workload 7, but the difference is I can call my experiment in my laptop by ssh instead of going directly to the lab computer.
Most of the changes were listed on Github repositories (RLKIT and DOODAD), but TL;DR, the problem was the run_experiment.py file from doodad was not using the GPU, so we add a line of code (ptu.set_gpu_mode(True)) in order to force the experiment to run with the lab's GPU. Furthermore, since we need to run in CPU and GPU, I decide to create two different docker images: one for CPU and one for GPU. They all use the same Dockerfile, except the requirements are different.
Zero-Shot Meta-Learning and Discussion for future plansIn this project, we decide to use the Batch RL in order to extend generalization in RL (the IQL algorithm; Implicit Q-Learning). However, we still need to test on DQN algorithm with different Atari experiments because we need to make sure that the preprocessing works while also comparing our DQN experiment with the ones that are in the "Playing Atari with Deep Reinforcement Learning" paper. Once we're done with that, we will incorporate the IQL algorithm and maybe use Compute Canada in order to speed things up.
In the next workload, I will read a paper related to IQL algorithm and post my personal notes and annotations related to the paper in the "Notes and References" section.
Implementation of Comet-MLIn order to look at our results while the experiments are running, I decide to add comet_ml library in my experiments so I can easily analyze the experiments' performance based on different graphs. All the changes in the code related to this section are in the README section of the Github repositories.
Testing on Breakout-v0
We start by testing our first DQN Breakout experiments:
Experiment 1: 3 000 epochs with learning rate of 0.001
Experiment 2: 5 000 epochs with max_path_length of 500 with original learning_rate of 3E-4
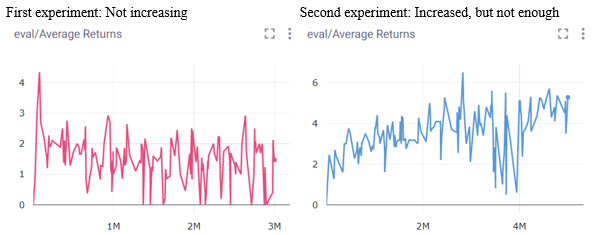
For now, the average total rewards seem to increase in the second experiment, but not enough. The baseline for Breakout-v0 was 168 (First Figure in workload 6) whereas our experiment was only 6 as the highest score. Because of that, we need to explore on other tasks: look at the replay buffer size, improve the preprocessing for the Atari games (for now, the number of channels is 1, but the papers uses 4), try another Atari environment instead of Breakout.
Report - Preliminary Version
I start by writing the first version of the report during this workload. Here are the complete sections:
- Introduction
- Related work
- Background and Math Framework
- The rest of the report is in bullet points
The goal for the next workload is to write about the IQL (zero-shot meta-learning) algorithm in the report (project method section) while improve the agent's performance during training.
Week of July 25th and August 1st
Deadline: August 7th
In order to be more familiar with the concept of generalization in RL, I took some notes from Glen's Generalization in Robotics' lesson for his RL course. Since we want to extend the definition of generalization in RL, the professor and I have discussed if we should use Meta Reinforcement Learning in order to let the agent perform better during new tasks. However, due to the complexity of this concept, we decided to focus on zero-shot meta learning by applying one of two methods: avoiding interference or batch RL. This type of Meta Learning is much more simple since I have already wrote a code for running an experiment where the agent only trains in one Atari environment.
Write Rough Draft for Presentation and ReportI also wrote a rough draft of the outline of my report in order to get some feedbacks as early as possible. One of the comments given by the professor was to define more about the definition of the success in my project. Initially, I only thought about comparing different average rewards for each Atari environment, but this doesn't give much insight about the effectiveness of using zero-shot meta learning in this project.
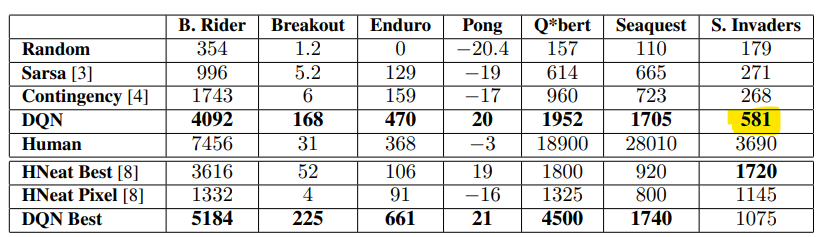
I have decided to test several experiments:
1. Run Space Invaders after training only one Atari environment (standard RL)
2. Run Space Invaders after training multiple Atari environments (zero-shot meta learning)
In terms of training on other Atari environments, I took ones that are similar to Space Invaders (shooting games) in order to make sure that the training can make the agent perform better while learning a new game which is Space Invaders.
I would measure success by comparing the average total reward with S.Invaders DQN (581) which is the result that is gotten from the 'Playing Atari with Deep Reinforcement Learning' paper, with the experiments that I just mentionned. This comparison helps us to draw conclusions, like which method is better for having a maximized average total rewards: the baseline, the standard RL or the zero-shot meta learning.
Create Virtual Machine in UbuntuThe first week's goal was to be able to run experiments with doodad and a docker image locally. I modified some codes in doodad because most of the codes are written for Linux (instead of Windows). However, when it comes to running the experiment through ssh in doodad, it became really difficult to debug and change the code for Windows configurations. So I decided to launch a virtual machine in Ubuntu 22.04.
During the second week, I decided to recreate another fork version of doodad since I will work on my virtual machine (Linux). The workload 5 was practically not really useful for my setup now since everything works without changing anything in the doodad library. However, it did help me to understand a bit more about doodad which makes the next steps much easier to execute.
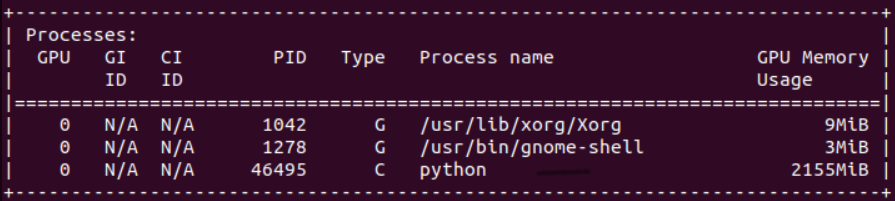
Test Atari experiments with doodad and docker through local computer and sshSo I started from the beginning by installing Anaconda, Git and Docker on my virtual machine and on my remote computer that is connected through ssh. I also decided to debug on VSCode instead of Pycharm in order to use the ssh extension (so I can connect to the lab computer and modify the files over there easily). Once that's done, I tested the experiments with doodad and docker and it worked. However, there was one issue that needs to solved: the GPU can't seem to detect the running experiment.
Use the lab's GPU to run experimentsThe first issue was the compatibility with the Pytorch installation inside the docker image. In order to fix that, I modified the Dockerfile by changing the cuda version to 11.3.0 instead of 10.2. I also changed the torch and torchvision to respectfully torch==1.10.0+cu113 and torchvision==0.11.1+cu113 since the compatibility with the lab's GPU is sm_86.


I used to run ssh since I ran the python file (experiment) locally. However, I decided to not use doodad for now and put all the rlkit and doodad code in the lab computer. I then created a nvidia-docker image with cuda version 11.3 and ubuntu version 18.04 so I can run my experiment with this image inside a container. This method works, but the moment I use doodad, it seems like nothing is appearing in the GPU processes which was the issue that I stated before.
Current solution: Run the experiment directly in the lab's computer instead of using doodadIn short, on my lap computer, I used the command docker run -it --gpus all rlkit:latest and inside the image runs the experiment with here_no_doodad mode (mode where we don't use doodad for running the experiments). This is not the most optimal solution, but for now the experiments will be run this way.

Week of July 17th
Deadline: July 25th
During the past workloads, the rlkit library was modified locally in my computer, but it became quite hard to keep track all the changes. I decided to fork the original repositories for rlkit and doodad in order to track down the changes I've done and the issues that I've encountered. From now on, all the changes that were made in the Github repositories will be shown here too. For the links of the repo, consult Notes and References.
Note: The changes on the Github repositories will be shown at the README section of each Github library (XinyuR1's fork version).
Test Atari experiments with doodad locallyI will also use doodad library in order to run experiments on different computers. This week's purpose is to also understand the code from doodad and test Atari experiments locally using doodad. The goal of workloads 5 and 6 is to complete the setup for doodad in order to run experiments from the lab computer with a docker image for rlkit.
Week of July 11th
Deadline: July 17th
This week's purpose was to focus on learning Docker and Dockerfile in order to use them eventually
in the main project. Finally, I created an image for the rlkit library that was inspired by SMiRL-Code library's
Dockerfile. Besides learning Docker, I also took some notes related to Meta-RL
(talk given Chelsea Finn) and learned some more Pytorch basics.
Update on the topic of the project:
Also, we were initially planning on applying the concept of generalization in different humanoids
for control tasks (morphology-agnostic learning). However, due to time restrictions, I decided
to fully focus on the concept of generalization using different Atari environments since I
already wrote two different CNN policies for different Atari environments.
The goal here is to experiment on three different environments using CNN policy. The agent trains
on three different games and it needs to learn the fourth game by itself (a new game that the agent
has never seen before) based on its experience.
Week of June 27th and July 4th
Deadline: July 8th
During the previous workload, I was testing the rlkit code with DQN-Cartpole (Project I), but no changes were made in the actual code. The professor and I have decided to work on another small project (exercise), by modifying some parts of the code: (1) Change the Cartpole environment into an Atari one (Breakout), (2) Preprocess the images from the breakout game, (3) Create a new policy from scratch using Pytorch CNN.
In order to prepare for the implementation in Pytorch, I followed a playlist of Pytorch tutorials (until workload 5). This also helps me to revise the basics of deep learning and backpropagation. In this workload, I suggested two different CNN Policies for the training of Breakout Game that are shown in the figure (at the end of this block). The plots for the training aren't done since this workload was mainly focused on building a CNN Policy. For the Atari Breakout mini-project, our next goal is to test the two models with a large number of epochs with CPU and GPU. I tested in my CPU for a very small amount of epochs, so the performance was obviously not great. In order to evaluate our CNN policy, we'll have to wait until we finish setup the doodad library and the docker image in order to run experiments from the lab computer.
Introduction to Dockerfile and GPUWe also had a brief introduction to Dockerfile this week, a topic that will be covered in the next workload.

Weeks of June 13th and June 20th
Deadline: June 26th
This section of workload focuses on gathering information that is related to the project, which is expanding the concept of generalization in RL. I've found two papers that mainly talk about DQN algorithm that is applied in multiple situations: the first paper talks about fluid mechanics, whereas the second one talks about the Atari Environment. Furthermore, we have found a paper that mainly talks about generalization in RL with zero-policy transfer. In terms of readings, the goal for the upcoming weeks is to find papers that talks more about multi-task and hierarchical learning.
Project I: DQN CartpoleI also start testing the RLKIT package by testing the DQN Algorithm with the cartpole environment. The RLKIT package mainly uses PyTorch to implement different methods, so I've decided to apply the same principles but with another library, which is stable-baseline3.
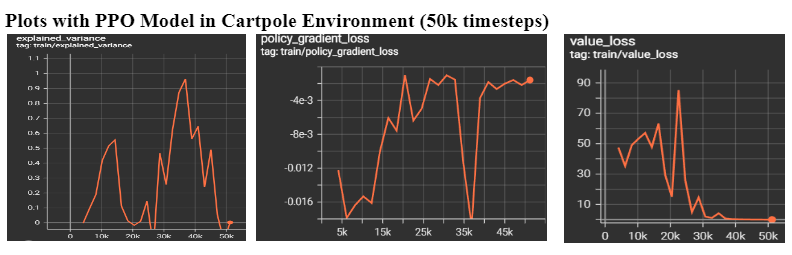
- Based on the value loss plot, we can see that the agent starts to learn between 0-25k timesteps and then the function decreases once the reward is stabilized.
- Based on the policy gradient loss plot, we can see a sudden drop in 35k timesteps, which means the training is successful during this specific amount of timesteps. We observe that the loss increases significantly once it reaches over 35k timesteps.
- Based on the explained variance, at 35k timesteps, the value is 0.9633, which is the highest value of explained variance in the plot. However, it is still not superior to 1, which means our PPO model can be improved with other alternatives.
Weeks of May 30th and June 6th
Deadline: June 12th
I start by taking notes about the basics of reinforcement learning. The lectures that I listened are given by professor Steven Brunton. The lectures give an overview of numerous RL methods that are model-based and model-free. I've decided to focus on the algorithm of Q-learning and DQN, since it will be useful for the main project. Since the mathematics and the logic behind the algorithms are quite complex, I've decided to link other papers or online tutorials that will explain deeply some of the concepts that I find interesting (i.e. Q-Learning).
Complete 3 small projects with OpenAIIn terms of implementation, I start by using the stable-baselines3 package and OpenAI. I will complete three small projects before diving into the concept of generalization in RL: Atari Game, Autonomous Driving and Creating a custom environment with Gym libraries.
Week of May 23rd
We review the basics and the importance of deep learning and reinforcement learning with the professor (back propagation, overfitting, etc.). We then discuss about the upcoming tasks that need to accomplish in order to be familiar with reinforcement learning. I decide to start with simple projects that are related with reinforcement learning.
Once I have completed some small projects, we then decide to work on the main project, which is morphology traning across different environments (expanding generalization of RL). If we have more time in the future, we can try to train with a fixed training data (off-policy idea).
Week of May 16th
Deadline: May 20th
We start by discussing the topic of the project. We have found one paper that talks about the concept of improving reinforcement learning with morphology-agnostic learning. The tasks that we've decided to train on were not confirmed yet, but we're going to use this paper as inspiration for this project. I've found some ideas that I can use as different tasks to train on different agents, like playing chess, the Atari Game, or training humanoids for control tasks (application of morphology-agnostic learning), but these are all brainstormed ideas for now.